在接手一个网站时,无论做什么诊断分析,都少不了检查robots文件,为什么有的网站天天发文章却未见收录,很有可能是因为被robots文件里的规则屏蔽搜索引擎抓取所导致的。那么什么是robots文件,对于一个网站它的作用的什么?本文白天为你详细介绍robots文件并教你robots文件正确的写法。

一、robots文件简介
简单来说就是一个以robots命名的txt格式的文本文件,是网站跟爬虫间的协议(你可以理解为搜索引擎蜘蛛抓取的规则),当搜索引擎发现一个新的站点时,首先会检查该站点是否存在robots文件,如果存在,搜索引擎则会跟据robots文件规定的规则来确定可以访问该站点的范围。
二、robots文件的作用
1.禁止搜索引擎收录网站,以保障网站的安全。比如一些网站是客户管理系统,只需要公司员工登录即可,属于并不想公开的私密信息,为了防止信息泄露就可以使用robots文件进行屏蔽抓取。
2.网站内的部分目录或内容如果不希望搜索引擎抓取,如WordPress的后台文件 wp-admin,管理仪表盘或其他页面,这些对搜索引擎无用的页面就可以借助robots文件来告诉搜索引擎不要抓取此目录下的内容,这样就可以让有限带宽的蜘蛛深入抓取更多需要被抓取收录的页面。
3.屏蔽一些动态链接,统一网站链接类型,集中权重。
三、robots文件写法
1、首先先来了解下robots文件里的内容由那几部分构成:
一个robots文件,不同的写法有不同的意义,常见的robots文件由User-agent、Allow、Disallow 等组成。另外,我们也经常会在robots文件中添加网站 sitemap 文件的链接以引导搜索引擎爬虫抓取。举一个例子:
User-agent: Baiduspider Allow: /wp-content/uploads/ Disallow: /w? Sitemap: https:/www.seobti.com/sitemap.xml
该例子中就包含有User-agent、Allow、Disallow 、Sitemap等。下面具体来解释下各自的作用。
User-agent: 该项的值用于描述搜索引擎robot的名字。在robots.txt文件中,至少要有一条User-agent记录。如果该项的值设为*(即:“User-agent:*”),则对任何robot均有效。另外如果只针对百度搜索引擎,则该项的值为:Baiduspider(即:“User-agent:Baiduspider”)。
Disallow: 该项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被 robot访问。
举例说明:
- “
Disallow: /help” 禁止robot访问 /help.html、/helpabc.html、/help/index.html,而 “Disallow:/help/”则允许robot访问/help.html、/helpabc.html,不能访问/help/index.html。 - “
Disallow: /”说明不允许搜索引擎robot访问该网站的所有url链接,需要注意的是robots.txt文件中,至少要有一条Disallow记录。
Allow: 该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL 是允许robot访问的。
举例说明:
- “
Allow:/hibaidu”允许robot访问/hibaidu.htm、/hibaiducom.html以及hibaidu这个目录内的所有内容,比如/hibaidu/com.html。 - 一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能。如:“
Disallow: /uploads/ Allow: /uploads/allimg/”只允许抓取/uploads/目录下的allimg文件。
以上是sitemap组成常见的部分,为了让robots写法更准确,我们还可以使用借助“*”and “$”来更精确的制定搜索引擎抓取规则。
“ *”and “ $”:robots文件中可以使用通配符“*”和“$”来模糊匹配url。“*” 匹配0或多个任意字符, “$” 匹配行结束符。
举例说明:
- “
Allow: /hibaidu可以写成Allow: /hibaidu*”,而Allow: /hibaidu$规定允许抓取的范围只限hibaidu这个目录及目录内的内容。其写法作用效果等同于Allow: /hibaidu/。 - Disallow: /*.asp$和Disallow: /*.asp两种写法,看似相似却规定的范围却大不相同。其中“Disallow: /*.asp$”指仅拦截以.asp结尾的网址,而“Disallow: /*.asp”则了拦截所有包含.asp的网址(可能有的.asp后还有一些参数),包括以.asp结尾的网址,也就是Disallow: /*.asp规定的范围包含了Disallow: /*.asp$的规定范围。
2、格式
在robots文件中,一个“User-agent”代表一条记录,且这样的记录可以包含一条或多条记录。如:
一条记录
User-agent: * Disallow: /template/ #该协议只有一条记录,该协议对所有搜索引擎有效
多条记录
User-agent: Baiduspider Disallow: /w? Disallow: /client/ User-agent: Googlebot Disallow: /update Disallow: /history User-agent: bingbot Disallow: /usercard #多条记录,针对不同的搜索引擎使用不同的协议
注意:“User-agent: *”中的“*”是通配符的意思, 也就是说该记录下的协议适用任何搜索引擎,而“User-agent: Baiduspider”中的“Baiduspider”是百度搜索引擎的爬取程序名称,也就是该协议只针对百度搜索引擎。
一般来说,优化的对象如果只针对国内的用户,那么就可以使用多条记录的方式来限制国外搜索引擎的抓取,以此可以节省服务器部分资源,减小服务器压力。
另外需要注意的是:robots.txt文件中只能有一条 “User-agent: *”这样的记录。
3、语法说明
这里主要列举几种比较常见的写法,如图2所示:
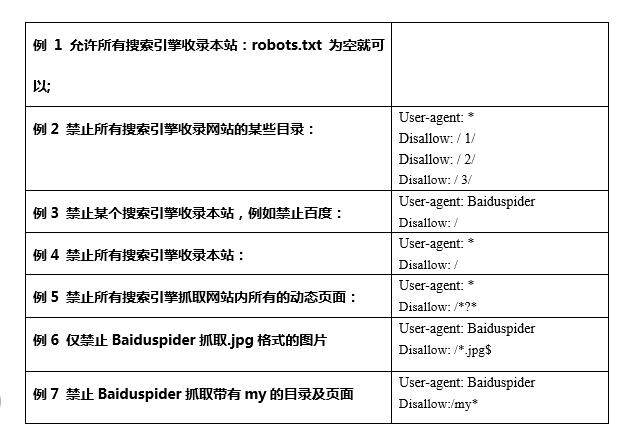
4、注释
为了方便理解,我们可以在robots文件里添加注释,在每一行以“ # ”开头即可(类似于服务器配置文件中的写法规则)。如图3所示:

四、使用robots文件需要注意的一些事项
1、robots文件应放在网站根目录,链接地址为:www.xxx.com/robots.txt;
2、鉴于不希望搜索引擎收录网站的隐私文件,可以使用robots文件来禁止抓取,但这样却正好可以被黑客所利用, 所以robots文件并不能保证网站的隐私,因此在robots规则时,可以使用“*”来模糊匹配。 如:Disallow:/my*;
3、“Disallow: /help”与“Disallow: /help/”规定的抓取范围有所不同,“/help”包含“/help.html、/help*.html、/help/index.html”等页面,而“/help/”不包含“/help.html、/help*.html”等页面。
五、robots的其他用法
除了使用 robots.txt 来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取外,robots还有另外一些写法—— Robots meta 标签。
Robots.txt文件主要是限制整个站点或者目录的搜索引擎访问情况,而Robots Meta标签则主要是针对一个个具体的页面。和其他的META标签(如使用的语言、页面的描述、关键词等)一样,Robots Meta标签也是放在页面中,专门用来告诉搜索引擎爬虫如何抓取该页的内容。
Robots Meta标签中没有大小写之分,name="robots"表示所有的搜索引擎,可以针对某个具体搜索引擎写为name="BaiduSpider"。
content部分有四个指令选项:index、noindex、follow、nofollow,指令间以“,”分隔。
- index指令告诉搜索机器人抓取该页面;
- follow指令表示搜索机器人可以沿着该页面上的链接继续抓取下去;
- noindex命令:告诉搜索引擎不允许抓取这个页面
- nofollow命令:告诉搜索引擎不允许从此页找到链接、拒绝其继续访问。
具体写法有以下四种:
<meta name="robots" content="index,follow"><!--可以抓取并索引本页,同时还可以顺着本页的链接继续抓取下去--> <meta name="robots" content="noindex,follow"><!--不能索引本页但可以顺着本页的链接继续抓取下去--> <meta name="robots" content="index,nofollow"><!--可以索引本页但不允许抓取本页的链接--> <meta name="robots" content="noindex,nofollow"><!--既不能索引本页同时也不可以抓取本页的链接-->
其中:
<meta name="robots" content="index,follow">
可以写成
<meta name="robots" content="all">
而
<meta name="robots" content="noindex,nofollow">
可以写成
<meta name="robots" content="none">
另外著名搜索引擎 Google 还增加了一个指令“archive”,可以限制Google是否保留网页快照。例如:
<meta name="googlebot" content="index,follow,noarchive">
需要注意的是并不是所有的搜索引擎都支持Robots meta标签写法。
过去的今天:
- 2020: 常用的SEO工具有哪些?(2)
原创文章,作者:白天,如若转载请注明出处:robots文件介绍、作用及写法
 微信扫一扫
微信扫一扫 

评论列表(2条)
这篇文章robots文件文章写的真详细,很受用!
搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息。
当该搜索引擎的robot发现一个新站点(比如https://www.seobti.com)时,它首先会检查确认该网站是否存在https://www.seobti.com/robots.txt文件。
如果robot发现含有该文件,那么它会根据这个文件的内容来确定它可以访问的范围,再根据范围来抓取网站内容;如果没有这个文件则默认网站允许抓取所有内容。
注意:robots.txt文件默认放在网站根目录下。